You've probably spent way too much on GPU cloud computing, watching your budget disappear while wrestling with complex setups that eat into your development time. The traditional cloud giants charge premium prices for basic GPU access, then bury you in configuration headaches that can take hours to resolve. Fortunately, a new generation of specialized GPU cloud platforms offers dramatically lower costs and developer-friendly features. We've tested the top providers to help you find the perfect balance of performance, simplicity, and savings for your AI projects.
TLDR:
GPU cloud computing refers to on-demand access to high-performance graphics processing units through cloud infrastructure, eliminating the need for expensive on-premises hardware. These services allow developers and organizations to rent powerful GPUs like NVIDIA A100s, H100s, and H200s for AI training, machine learning inference, and high-performance computing workloads.
Unlike traditional CPU-based cloud computing, GPU cloud services excel at parallel processing tasks needed for AI applications. From training LLMs to running complex deep learning algorithms, GPUs handle thousands of simultaneous calculations that would take CPUs much longer to complete.
The pay-as-you-go model makes advanced computing resources accessible to startups, researchers, and enterprises without massive upfront investments. Instead of purchasing a $40,000 H100 GPU, teams can access the same hardware for a few dollars per hour.
The global GPU as a service market is experiencing explosive growth, driven by increasing demand for AI and machine learning features across industries.
The GPU cloud market reached $3.80 billion in 2024 and is projected to hit $12.26 billion by 2030. This growth reflects how important GPU computing has become for organizations building AI-powered applications.
For teams looking at options, understanding the cost differences between providers is important. We've analyzed the cheapest cloud GPU providers to help you make informed decisions about your AI infrastructure needs.
Our evaluation framework focuses on real-world factors that matter most to developers and organizations deploying AI workloads in production. We assessed each provider across five key dimensions that directly impact project success and budget performance.
Performance and Hardware Access
We tested GPU availability, including access to latest-generation hardware like H100s and A100s. Hardware mismatches frequently cause cost overruns in cloud environments, making proper GPU selection important for project economics.
Pricing Transparency
Cost predictability separates good providers from great ones. We analyzed hourly rates, hidden fees, and billing complexity to identify services that offer genuine value without surprise charges.
Developer Experience
Setup complexity can make or break adoption. We looked at onboarding processes, CLI tools, IDE integrations, and pre-configured environments that reduce time-to-first-model.
The best GPU cloud services eliminate infrastructure headaches so teams can focus on building AI applications instead of managing servers.
Scalability and Reliability
We considered instance scaling options, uptime guarantees, and support quality. Teams need confidence their training jobs won't fail due to provider limitations.
Our rankings reflect practical considerations instead of synthetic benchmarks. We focused on services offering clear value propositions through cost savings, ease of use, or specialized features that solve common GPU computing challenges.
Understanding how to choose the right GPU for your specific workloads remains important regardless of which provider you select.
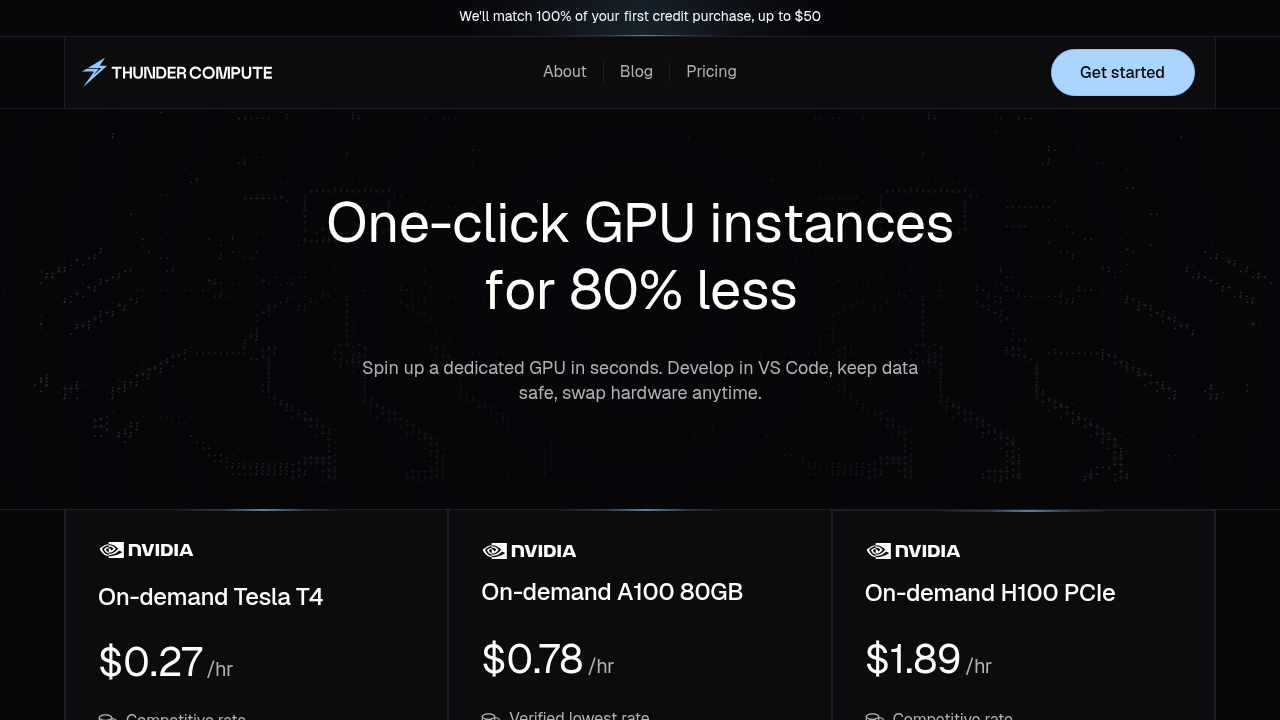
Thunder Compute delivers exceptional value through ultra-low pricing and developer-focused simplicity, making high-performance GPUs accessible to teams of all sizes. The service offers NVIDIA A100s starting at just $0.66/hour and T4s at $0.27/hour, representing up to 80% savings compared to traditional cloud providers while maintaining enterprise-grade performance and reliability.
The service excels at removing typical cloud complexity. No VPC configuration or IAM policies required - just launch an instance and start coding. This simple approach makes Thunder Compute particularly valuable for startups and researchers who need powerful GPUs without DevOps overhead.
Thunder Compute's new GPU virtualization technology allows efficient resource use that translates directly into customer savings. The Y Combinator-backed company focuses exclusively on AI/ML workloads, with every feature serving developers building intelligent applications.
Thunder Compute eliminates infrastructure headaches so teams can focus on building AI applications instead of managing servers.
Bottom line: The most cost-effective solution for AI teams seeking professional-grade GPU access without enterprise complexity. Learn more about cutting cloud GPU costs during development phases.
RunPod operates as a developer-focused GPU service that provides containerized compute instances with per-second billing. The service supports both secure cloud and community cloud tiers, offering access to GPUs ranging from consumer RTX cards to enterprise H100s through a web-based interface and pre-built templates.
RunPod's per-second billing reduces costs for short-duration workloads and experimentation phases. Their serverless GPU functions allow code execution without provisioning full instances, making it attractive for intermittent computing needs.
The template marketplace provides pre-configured environments for popular frameworks like PyTorch and TensorFlow. Community cloud tier offers lower-cost access through shared infrastructure, though this comes with trade-offs in reliability and security guarantees.
RunPod's containerized approach appeals to developers comfortable with Docker workflows. The service handles basic infrastructure management while giving users control over their computing environment.
RunPod's per-second billing model can greatly reduce costs for teams running short experiments or batch processing jobs.
Limitations: Community cloud tier may experience variable reliability and security concerns for enterprise workloads. Setup complexity increases compared to simpler alternatives.
Bottom line: Suitable for developers who value flexible billing but can manage infrastructure trade-offs. For detailed comparisons, check our analysis of RunPod alternatives and detailed RunPod pricing comparison.
Lambda Labs targets AI researchers and academic institutions with ready-to-use deep learning environments and high-performance clustering features. The service provides access to NVIDIA H100, H200, and A100 GPUs with pre-installed frameworks and research-focused tooling.
Lambda Labs excels at multi-GPU distributed training through one-click cluster deployment. Their Quantum-2 InfiniBand networking allows high-throughput communication between nodes, making it valuable for large-scale model training that requires tight coordination across multiple GPUs.
The service comes with pre-configured deep learning environments featuring popular frameworks like PyTorch, TensorFlow, and JAX. This eliminates setup time for researchers who want to jump straight into experimentation without managing dependencies.
Academic pricing programs and research institution partnerships make Lambda Labs attractive to universities and research organizations. They understand the specific needs of academic workflows and provide tooling designed for research reproducibility.
Lambda Labs offers GPU cloud services tailored for AI developers needing powerful hardware for intensive training and inference workloads.
Limitations: Pricing tends to be higher than specialized cost-focused providers for equivalent hardware configurations. The research-focused approach may include features that commercial teams don't need, potentially increasing costs.
Bottom line: Appropriate for research teams requiring ready-made environments but less cost-conscious than commercial users. For detailed comparisons, see our Lambda Labs vs Thunder Compute analysis and check out Lambda Labs alternatives for budget-focused options.
Vast.ai functions as a marketplace connecting users with GPU providers through a bidding system. The service aggregates spare capacity from individual hosts and data centers, creating a distributed network of available hardware at variable pricing.
The marketplace model allows competitive bidding that can drive prices well below traditional fixed rates. Users can find consumer-grade RTX cards alongside enterprise GPUs depending on what hosts make available at any given time.
Vast.ai's real-time availability monitoring shows current pricing across different GPU types and locations. The bidding system rewards flexibility: teams willing to accept potential interruptions can access hardware at substantial discounts compared to guaranteed instances.
The service supports both on-demand and interruptible workloads. Interruptible instances offer the lowest rates but may terminate when higher bidders claim the hardware, making them suitable only for fault-tolerant applications.
The marketplace approach can provide major cost savings for experimental workloads where guaranteed uptime isn't critical.
Limitations: Variable reliability and potential job interruptions make Vast.ai unsuitable for production deployments requiring consistent uptime. Quality varies greatly between individual hosts, creating unpredictable performance characteristics.
Bottom line: Best for experimental workloads where cost matters more than guaranteed availability. For detailed comparisons, see our Vast.ai vs Thunder Compute analysis and check out Vast.ai alternatives for more reliable options.
CoreWeave operates as an AI-first cloud offering high-density GPU clusters designed for enterprise-scale AI workloads. The service targets organizations requiring massive compute resources with advanced networking and custom orchestration features.
CoreWeave's infrastructure focuses on density and performance through specialized data center configurations optimized for AI training. Their clusters feature advanced networking topologies that allow efficient multi-node communication for distributed training scenarios.
The service provides fractional GPU usage options, allowing teams to optimize costs by sharing GPU resources across multiple workloads. This approach works well for inference applications that don't require full GPU dedication.
Custom job scheduling systems give enterprise teams granular control over resource allocation and workload prioritization. CoreWeave's container orchestration handles complex deployment scenarios that require coordination across multiple GPU nodes.
Support for cutting-edge hardware includes H100 and upcoming B200 architectures, positioning CoreWeave for teams working with the largest AI models requiring maximum computational power.
CoreWeave's enterprise focus delivers advanced infrastructure features but requires deep technical expertise to use effectively.
Limitations: The complexity and enterprise orientation make CoreWeave less accessible for individual developers and small teams. Pricing structures typically favor large-scale commitments over flexible usage patterns.
Bottom line: Designed for organizations with substantial compute requirements and dedicated infrastructure teams. For detailed comparisons, see our CoreWeave vs Thunder Compute analysis and CoreWeave GPU pricing review.
The table below compares key features across the top GPU cloud providers to help you make informed decisions based on your specific requirements and budget constraints.
Thunder Compute stands out with the cheapest A100 pricing at $0.66/hour, beating competitors by a wide margin while maintaining enterprise reliability. The native VS Code integration and hot-swappable GPUs provide unique developer productivity advantages.
Thunder Compute delivers enterprise-grade reliability at startup-friendly prices, making advanced AI development accessible to teams of all sizes.
For complete A100 cost analysis across providers, check our detailed A100 GPU pricing comparison
Thunder Compute combines exceptional cost savings with developer productivity features that eliminate common friction points in GPU cloud computing. The service's unique value proposition stems from its focus on making high-performance computing truly accessible and available to everyone.
The 80% cost savings compared to traditional providers represents real budget relief for teams building AI applications. A typical A100 training job that costs $200 on AWS runs for $40 on Thunder Compute, freeing up resources for experimentation and iteration.
Thunder Compute's singular focus on AI/ML infrastructure means every feature serves developers building intelligent applications. The native VS Code integration, hot-swappable GPUs, and pre-configured environments eliminate setup friction that typically consumes hours of development time.
Unlike general cloud providers with complex networking requirements, Thunder Compute abstracts away infrastructure complexity while maintaining full control over your computing environment. This approach particularly benefits startups building AI applications where development speed directly impacts competitive advantage.
Thunder Compute eliminates the trade-off between cost and simplicity that forces teams to choose between budget constraints and productivity.
The transparent pricing model removes billing uncertainty that plagues other providers. Teams can predict costs accurately and scale resources confidently without worrying about surprise charges or complex commitment structures.
Bottom line: Thunder Compute delivers enterprise-grade reliability at startup-friendly prices, making advanced AI development accessible to teams of all sizes.
You can save up to 80% on GPU costs by switching from traditional cloud providers to specialized services like Thunder Compute, where A100s cost $0.66/hour compared to AWS's much higher rates.
Hot-swappable GPUs allow you to upgrade your hardware (like switching from a T4 to an A100) without rebuilding your environment or losing your work progress. This saves hours of setup time compared to traditional cloud providers where GPU changes require provisioning entirely new instances.
With modern GPU cloud platforms, you can deploy instances in seconds using one-click deployment or CLI commands. Thunder Compute and similar services eliminate the complex VPC and IAM configuration typically required by traditional cloud providers.
Per-second billing benefits short experiments and batch jobs under an hour, while hourly billing works better for longer training sessions and development work. Consider your typical workload duration and whether you frequently start/stop instances.
Community cloud tiers offer lower costs through shared infrastructure but may have variable reliability and security limitations. Enterprise tiers provide guaranteed uptime, dedicated resources, and enhanced security, making them suitable for production workloads despite higher costs.
The GPU cloud market offers plenty of options, but the cost differences are massive. Thunder Compute's up to 80% savings compared to traditional providers means you can run more experiments and build better models without breaking your budget. The combination of transparent pricing, developer-friendly features, and enterprise reliability makes advanced AI development accessible to teams of any size. Your next breakthrough shouldn't wait for budget approval.
